Unicorn
前记
经由Rails部署之道看到GitHub从Mongrel迁移到了Unicorn的相关介绍,可惜是英文的,所以,边看边翻译。注:文章写于2009年9月。
原文地址: https://github.com/blog/517-unicorn
原文
We’ve been running Unicorn for more than a month. Time to talk about it.
已经运行Unicorn一个多月了,是时候讨论讨论了。
What is it?
Unicorn is an HTTP server for Ruby, similar to Mongrel or Thin. It uses Mongrel’s Ragel HTTP parser but has a dramatically different architecture and philosophy.
Unicorn是一个Ruby的HTTP服务器。和Mongrel以及Thin类似,其使用Mongrel的Ragel HTTP解析器,但其架构和设计哲学截然不同。
In the classic setup you have nginx sending requests to a pool of mongrels using a smart balancer or a simple round robin.
在传统的步骤中,使用nginx发送请求到mongrel集群池中,其中Mongrel集群可使用智能的负载均衡器或一个简单的round robin(循环服务,我想可能是在循环中将请求依次发送给mongrel集群)。
Eventually you want better visibility and reliability out of your load balancing situation, so you throw haproxy into the mix:
最终,可能想要更好的可视化和可靠性,不仅仅是负载均衡情况。所以,又将haproxy添加进去了:
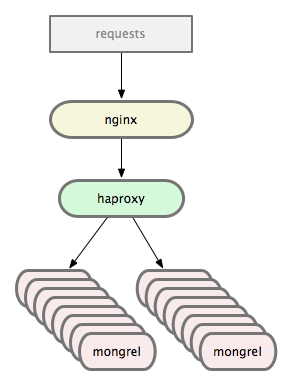
Haproxy: 可靠的、高性能的Tcp/HTTP负载准衡器(软件实现)。高性能的原因在于:实现了事件驱动,单一进程的模型,支持极大的并发连接数。官方的地址:http://www.haproxy.org/, Github代码库镜像:https://github.com/haproxy/haproxy
Which works great. We ran this setup for a long time and were very happy with it. However, there are a few problems.
上面的架构工作的非常的好,运行了相当长的时间并且对次很满意,但是也存在一些问题。
Slow Actions
When actions take longer than 60s to complete, Mongrel will try to kill the thread. This has proven unreliable due to Ruby’s threading. Mongrels will often get into a “stuck” stage and need to be killed by some external process (e.g. god or monit).
当有的动作需要花费超过60秒的时间处理时,Mongrel将会尝试杀死线程(Rails是一个单线程的程序)。由于Ruby线程的原因,事实证明,杀死线程是相当不稳定的,这通常使得Mongrels陷入了”卡顿”的情况,并且需要外部进程将其杀死(比如god或者monit)。
Yes, this is a problem with our application. No action should ever take 60s. But we have a complicated application with many moving parts and things go wrong. Our production environment needs to handle errors and failures gracefully.
的确,这是我们(github)应用的问题。几乎没有什么应用需要花费超过60秒的时间,但是,github是一个相当复杂且动态变化的应用程序,所以,事情越变越糟,需要处理的错误和失效与日剧增。
Memory Growth
We restart mongrels that hit a certain memory threshhold. This is often a problem with parts of our application. Engine Yard has a great post on memory bloat and how to deal with it.
重启mongrels将会触发内存阈值。这通常也是github所面临的一个问题。 Engine Yard(一家云端应用管理平台)博客中有一个关于内存膨胀(memory bloat)的很好的文章here。
Like slow actions, however, it happens. You need to be prepared for things to not always be perfect, and so does your production environment. We don’t kill app servers often due to memory bloat, but it happens.
如同slow actions一样,必须明白生活并不总是完美的,生产环境也是一样的。由于内存膨胀,所以不常杀死应用服务器,但内存膨胀总是时常发生。
Slow Deploys
When your server’s CPU is pegged, restarting 9 mongrels hurts. Each one has to load all of Rails, all your gems, all your libraries, and your app into memory before it can start serving requests. They’re all doing the exact same thing but fighting each other for resources.
当你的进程准备重启9个mongrel时,每个mongrel进程在开始接受请求前,都将加载所有的Rails,所有的gem包,以及所有的类库到内存中。这些进程做着完全相同的事情,却为了争夺资源而彼此干架。
During that time, you’ve killed your old mongrels so any users hitting your site have to wait for the mongrels to be fully started. If you’re really overloaded, this can result in 10s+ waits. Ouch.
在所有的Mongrels进程都被干掉,而新的mongrel又未完全启动时,如果用户访问了网站,上帝,他将要等待10以上。
There are some complicated solutions that automate “rolling restarts” with multiple haproxy setups and restarting mongrels in different pools. But, as I said, they’re complicated and not foolproof.
确实存在一些复杂的解决方案,可以在haproxy的设置下自动回滚,并在不同池子中重启mongrels。但是,相当的复杂,又容易出错。
Slow Restarts
As with the deploys, any time a mongrel is killed due to memory growth or timeout problems it will take multiple seconds until it’s ready to serve requests again. During peak load this can have a noticeable impact on the site’s responsiveness.
在部署时,由于内存增长或者超时的问题,任何mongrel都将被杀死。并且在进程重新服务响应时,将耗费数秒。在峰值负载期间,这将对站点的响应造成不可忽略的影响。
Push Balancing
With most popular load balancing solutions, requests are handed to a load balancer who decides which mongrel will service it. The better the load balancer, the smarter it is about knowing who is ready.
大多数流行的负载均衡解决方案,请求由负载均衡器处理,并决定哪个mongrel为其提供服务。负载均衡越好,它就越知道哪个服务进程准备就绪。
This is typically why you’d graduate from an nginx-based load balancing solution to haproxy: haproxy is better at queueing up requests and handing them to mongrels who can actually serve them.
这也是为何要从基于nginx的负载均衡升级到haproxy: haproxy精于轮寻,并且知道将其发送给可以处理其的mongrels服务器。
At the end of the day, though, the load balancer is still pushing requests to the mongrels. You run the risk of pushing a request to a mongrel who may not be the best candidate for serving a request at that time.
即使今天,负载均衡器依然只是推送请求给mongrels,这就存在可能将请求推送给不是最佳选择的服务器。
Unicorn

Unicorn的Logo,感觉有点像《神奇宝贝》中的梦靥,不过看起来更加的愤怒一些,色彩鲜艳一些。
Unicorn has a slightly different architecture. Instead of the nginx => haproxy => mongrel cluster setup you end up with something like:
Unicorn有着稍微不同的架构。和nginx => haproxy => mongrel cluster这样的web服务架构不同的是,Unicorn看起来像是这样的:
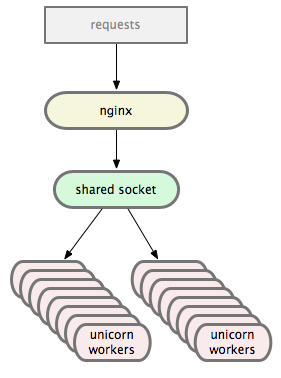
nginx sends requests directly to the Unicorn worker pool over a Unix Domain Socket (or TCP, if you prefer). The Unicorn master manages the workers while the OS handles balancing, which we’ll talk about in a second. The master itself never sees any requests.
nginx将请求直接通过Unix的套接字(或者TCP)发送给Unicorn工作进程池。 Unicorn master进程管理这所有的workers进程, 操作系统负责处理均衡。主进程本身看不到任何请求。
下面是nginx => haproxy和nginx => unicorn配置之间唯一的不同:
# port 3000 is haproxy
upstream github {
server 127.0.0.1:3000;
}
# unicorn master opens a unix domain socket
upstream github {
server unix:/data/github/current/tmp/sockets/unicorn.sock;
}
When the Unicorn master starts, it loads our app into memory. As soon as it’s ready to serve requests it forks 16 workers. Those workers then select() on the socket, only serving requests they’re capable of handling. In this way the kernel handles the load balancing for us.
当Unicorn主进程启动时,将会把应用程序加载到内存中。在其准备接受HTTP处理时,它fork出16个工作进程。这些工作进程使用select()系统调用监听套接字,并且只护理他们自己能处理的请求。此时,系统内核负责负载均衡。
Slow Actions
The Unicorn master process knows exactly how long each worker has been processing a request. If a worker takes longer than 30s (we lowered it from mongrel’s default of 60s) to respond, the master immediately kills the worker and forks a new one. The new worker is instantly able to serve a new request – no multi-second startup penalty.
Unicorn主进程知道每个工作进程处理一个请求的处理所耗费的精确的时间。如果某个工作进程花费了超过30s(Mongrel中默认为60秒),主进程立即将其干掉,并重新fork出一个新的进程。新的工作进程可以立刻处理请求,而不需要数秒的等待时间。
When this happens the client is sent a 502 error page. You may have seen ours and wondered what it meant. Usually it means your request was killed before it completed.
此时,客户端将会收到502的错误页面,这是因为请求在完成前被干掉了。
Memory Growth
When a worker is using too much memory, god or monit can send it a QUIT signal. This tells the worker to die after finishing the current request. As soon as the worker dies, the master forks a new one which is instantly able to serve requests. In this way we don’t have to kill your connection mid-request or take a startup penalty.
当工作进程使用了太多的内存时,god或者monit将对其发送QUIT,告诉工作进程,处理完手下的请求,就去死吧。每当旧的工作进程死后,master进程就会立即fork一个新进程,并且其可以立即工作。以这种方式,就不会中途杀死连接,也不会存在启动代价。
Slow Deploys
Our deploys are ridiculous now. Combined with our custom Capistrano recipes, they’re very fast. Here’s what we do.
现在,部署是相当荒唐的。结合custom Capistrano recipes,部署非常的快。
First we send the existing Unicorn master a USR2 signal. This tells it to begin starting a new master process, reloading all our app code. When the new master is fully loaded it forks all the workers it needs. The first worker forked notices there is still an old master and sends it a QUIT signal.
首先,给已存在的Unicorn主进程发送USR2信号。这表明,将要启动一个新的主服务进程了,并重新加载应用程序代码。当新的主进程完全加载后,其将fork出其需要的worker进程。如果第一个工作进程注意到,老的主进程依然存在,它将发送QUIT信号。
When the old master receives the QUIT, it starts gracefully shutting down its workers. Once all the workers have finished serving requests, it dies. We now have a fresh version of our app, fully loaded and ready to receive requests, without any downtime: the old and new workers all share the Unix Domain Socket so nginx doesn’t have to even care about the transition.
当老的主进程接受到QUIT信号,其将逐渐关闭所有的工作进程。一旦,老的主进程手下的所有工作进程停止接受请求,它将会杀死自己。此时,我们就有了一个全新的app,完全加载完成并准备接受请求,其间没有任何时延:老的工作进程和新的工作进程共享UNIX套接字,所以,Nginx根本不需要关心其间的过度。
We can also use this process to upgrade Unicorn itself.
当然,还可以利用上述的处理过程来升级Unicorn自身。
What about migrations? Simple: just throw up a “The site is temporarily down for maintenance” page, run the migration, restart Unicorn, then remove the downtime page. Same as it ever was.
那迁移又如何呢?很简单,只要先抛出”The site is temporarily down for maintenance”页面,然后运行迁移,重启unicorn。然后再移除临时页面。
Slow Restarts
As mentioned above, restarts are only slow when the master has to start. Workers can be killed and re-fork() incredibly fast.
正如上面提到的那样,仅当master进程启动时,会减缓服务。工作进程被杀死并且重启的速度极其迅猛。
When we are doing a full restart, only one process is ever loading all the app code: the master. There are no wasted cycles.
当全部重启时,只有主进程需要加载所有应用程序的代码,这样并不浪费任何资源。
Push Balancing
Instead of being pushed requests, workers pull requests. Ryan Tomayko has a great article on the nitty gritties of this process titled I like Unicorn because it’s Unix.
与推送请求不同的是,工作进程主动接受请求。Ryan Tomayko](http://github.com/rtomayko)写了一篇极好好的关于这个主题的文章,名为I like Unicorn because it’s Unix.
Basically, a worker asks for a request when it’s ready to serve one. Simple.
简而言之,工作进程在准备好处理请求时,主动接受请求。
Migration Strategy
So, you want to migrate from thin or mongrel cluster to Unicorn? If you’re running an nginx => haproxy => cluster setup it’s pretty easy. Instead of changing any settings, you can simply tell the Unicorn workers to listen on a TCP port when they are forked. These ports can match the ports of your current mongrels.
所以,想把thin或者mongrel cluster迁移到Unicorn?如果,你恰好运行着nginx => haproxy => cluster这样的架构,相当的完美。不需要作出任何修改,在Unicorn主进程开始fork起那,可以简单的指定Unicorn工作进程监听TCP端口。这些端口将匹配mongrels当前的端口。
Check out the Configurator documentation for an example of this method. Specifically this part:
参考Configurator documentation中的配置样例,特别是如下的这一部分:
after_fork do |server, worker|
# per-process listener ports for debugging/admin/migrations
addr = "127.0.0.1:#{9293 + worker.nr}"
server.listen(addr, :tries => -1, :delay => 5, :tcp_nopush => true)
end
This tells each worker to start listening on a port equal to their worker # + 9293 forever – they’ll keep trying to bind until the port is available.
如上的配置将告诉每个工作进程监听值为其自身端口值+9293 - 进程将一直尝试,知道相应的端口可用。
Using this trick you can start up a pool of Unicorn workers, then shut down your existing pool of mongrel or thin app servers when the Unicorns are ready. The workers will bind to the ports as soon as possible and start serving requests.
使用如上的技巧,首先启动一堆Unicorn workers工程。然后,在服务器准备就绪时,关闭已有的mongrel进程。Uncorn工作进程将立即绑定端口,并开始处理请求。
It’s a good way to get familiar with Unicorn without touching your haproxy or nginx configs.
(For fun, try running “kill -9” on a worker then doing a “ps aux”. You probably won’t even notice it was gone.)
Once you’re comfortable with Unicorn and have your deploy scripts ready, you can modify nginx’s upstream to use Unix Domain Sockets then stop opening ports in the Unicorn workers. Also, no more haproxy.
一旦,适应了Unicorn并准备好了部署脚本,可以修改nginx的上流设置,使用Unix套接字(Linux系统大量使用的UNIX套接字,具体可以通过netstat tlnp命令进行查看),然后关闭将在Unicorn工作进程中使用的端口。
GitHub’s Setup
Here’s our Unicorn config in all its glory.
这里是Github的Unicorn配置。
I recommend making the SIGNALS documentation your new home page and reading all the other pages available at the Unicorn site. It’s very well documented and Eric is focusing on improving it every day.
其他的相关的配置可以参考Unicorn文档,其中,最重要的是关于信号的描述,需要认真的,仔细的阅读。
Speed
Honestly, I don’t care. I want a production environment that can gracefully handle chaos more than I want something that’s screaming fast. I want stability and reliability over raw speed.
真心不太关注速度。相比快速流处理,更想要一个能处理混沌的、稳定的、可靠的生产环境。
Luckily, Unicorn seems to offer both.
幸运的是,Unicorn同时满足了两方面的需求,快速,可靠,稳定。
Here are Tom’s benchmarks on our Rackspace bare metal hardware. We ran GitHub on one machine and the benchmarks on a separate machine. The servers are 8 core 16GB boxes connected via gigabit ethernet.
这里是Tom在Rackspace裸机上的基准测试。在某个机器上运行Github,并在另一个单独的机器上运行基准测试,服务器配置为:8核,16G,G比特的以太网。
What we’re testing is a single Rails action rendering a simple string. This means each requeust goes through the entire Rails routing process and all that jazz.
测试内容是测试那些渲染单个字符串的单个Rails动作。这意味着,每个请求都将穿过这个Rails的路由处理过程。
Mongrel has haproxy in front of it. unicorn-tcp is using a port opened by the master, unicorn-unix with a 1024 backlog is the master opening a unix domain socket with the default “listen” backlog, and the 2048 backlog is the same setup with an increased “listen” backlog.
Mongrel使用Haproxy作为其前端,unicorn-tcp使用由主进程打开的端口号,1024 backlog的unicorn-unix表示以默认的backlog的方式打开一个unix套接字,2048 backlog的unicorn-unix是一个升级版的backlog。
These benchmarks examine as many requests as we were able to push through before getting any 502 or 500 errors. Each test uses 8 workers.
基准测试检测了我们所能推送的最大量的请求,直到遇到502或者500错误。每个测试有8个工作进程。
mongrel
8: Reply rate [replies/s]:
min 1270.4 avg 1301.7 max 1359.7 stddev 50.3 (3 samples)
unicorn-tcp
8: Reply rate [replies/s]:
min 1341.7 avg 1351.0 max 1360.7 stddev 7.8 (4 samples)
unicorn-unix (1024 backlog)
8: Reply rate [replies/s]:
min 1148.2 avg 1149.7 max 1152.1 stddev 1.8 (4 samples)
unicorn-unix (2048 backlog)
8: Reply rate [replies/s]:
min 1462.2 avg 1502.3 max 1538.7 stddev 39.6 (4 samples)
Conclusion
Passenger is awesome. Mongrel is awesome. Thin is awesome.
Passenger、Mongrel、Thin都是恐怖的。
Use what works best for you. Decide what you need and evaluate the available options based on those needs. Don’t pick a tool because GitHub uses it, pick a tool because it solves the problems you have.
使用那些对你而言是最好的工具。根据需求,并评估基于需求的选项。不要因为Github使用某个工具而使用某个工具,要使用那些能解决难题的工具。
Unicorn isn’t for every app. But it’s working great for us.
Unicorn并不适合任何一个app,但它适合github的需求。
We use Thin to serve the GitHub Services and I use Passenger for many of my side projects.
当然,Github也使用Thin来提供一些服务,个人使用Passenger实现自己项目。
后记
最初的时候,从《代码的未来》上看到Unicorn服务器,后来,在《理解Unix进程》中有一次看到了Unicorn服务器。总体感觉,Ruby社区是一个非常活力的社区。大家都很热衷制造各式各样的不同用途的轮子。
最近,进入了倦怠期。本文,创建于10月8号,直到10月16号才全部完成。看书也不那么燃了,时常感觉到很没意思,就像最近看《妖尾》一样,看来,需要寻找新的刺激点,重拾一些遗忘的东西。
傲娇的使用Disqus